作者简介:周铁军 (1956-),男,湖南益阳人,教授,硕士生导师 ,主要从事网络安全、数据挖掘的研究
Application of Apriori algorithm on garden information system
ZHOU Tie-jun, ZHANG Hao, TAN Li-zhi
School of Computer and Information Engineering, Central South University of Forestry and Technology, Changsha 410004, Hunan, China
备注
摘要
全文
图/表
参考文献
近年来 ,关联规则挖掘己经成为数据挖掘技术中的一个研究热点。根据长沙市园林信息管理系统的发展要求,并结合长沙市园林业的实际情况,构架设计了园林管理信息系统,分析了数据挖掘在园林行业中的应用,用 Apriori算法对园林病虫害数据库中的病虫数据进行了关联分析,找出各种病虫害在相关属性中的分布规律,为决策者提供有参考价值的信息。
In recent years, the mining of association rules technique has became a research hotspot. According to the requirements of the development of Changsha city landscape information management system, and taking into account Changsha city garden industry actual situation, the structural design of landscape management information system was set up, the application of data mining in the landscape industry was analyzed. By using traditional Apriori algorithm, the data of plant diseases and insect pests in the ornamental diseases and pests database were connectedly analyzed, the distribution law of the relevant attribute of diseases and insect pests was found out, the results provided some valuable information for decision-makeing.
引言
关联规则挖掘是数据挖掘技术中一个非常重要的研究内容,它是Agrawal 等人首先提出的,关联规则挖掘是找出同一个事件中不同项之间的相关性,即找出事件中频繁出现的项集或该项集的所有子集,以及这些项集之间的相互关联性,然后从这些项集中找出关联知识。近年来,国内外众多的学者对关联规则挖掘问题进行了大量的研究,他们的工作涉及到关联规则挖掘理论的探索、原有关联规则挖掘算法的改进[1] 新关联规则挖掘算法的设计, 并行关联规则挖掘算法设计以及增量关联规则挖掘算法设计等问题。另外,在关联规则挖掘算法的可扩展性以及应用方面,许多学者也进行了研究。
1 关联规则Apriori算法概述
关联规则挖掘(Association Rules Mining) 是发现数据库中数据项之间蕴含规则的一种技术。最初是针对购物篮分析[2] 提出的, 数据分析人员从交易数据库中顾客购买的不同商品记录, 找到顾客的购买行为, 然后,经营者利用这些购买行为指导商品货架设计、货存安排以及根据购买行为对客户进行分类。虽然关联规则挖掘是伴随零售业的决速发展而产生的,但是关联规则挖掘的应用绝不仅仅体现在零售业上,它还体现在金融业、电信业、制造业、保险业等,所以展开关联规则算法的研究具有重要的理论意义和应用价值[3]。
Apriori 算法是一种挖掘关联规则的算法,是Agrawal 等设计的一个基本算法,这是一个采用两阶段挖掘的思想,并且基于多次扫描事务数据库来执行的。 Apriori算法的设计可以分解为两步骤来执行挖掘:
a.从事务数据库( D)中挖掘出所有频繁项集。
支持度大于最小支持度 minSup的项集(Itemset)称为频集( Frequent Itemset)。首先需要挖掘出频繁 1-项集;然后,继续采用递推的方式来挖掘频繁 k-项集( k>1),具体做法是:在挖掘出候选频繁 k-项集( Ck)之后,根据最小置信度 minSup来筛选,得到频繁 k-项集。最后合并全部的频繁 k-项集( k>0)。挖掘频繁项集的算法描述如下 [4]:
(1) L1 = find_frequent_1-itemsets(D); //挖掘频繁 1-项集,比较容易
(2) for (k = 2;Lk-1 ≠Φ ;k++) {
(3)Ck = apriori_gen(Lk-1 ,min_sup); //调用 apriori_gen方法生成候选频繁 k-项集
(4)for each transaction t ∈ D{ //扫描事务数据库 D
(5)Ct = subset(Ck,t);
(6)for each candidate c ∈ Ct
(7)c.count++; //统计候选频繁 k-项集的计数
(8)}
(9)Lk ={c ∈ Ck|c.count ≥ min_sup} //满足最小支持度的 k-项集即为频繁 k-项集
(10) }
(11)return L= ∪ k Lk; //合并频繁 k-项集( k>0)
b.基于第 1步挖掘到的频繁项集,继续挖掘出全部的频繁关联规则。
置信度大于给定最小置信度的关联规则称为频繁关联规则( Frequent Association Rule)。在这一步,首先需要从频繁项集入手,首先挖掘出全部的关联规则(或者称候选关联规则),然后根据最小置信度来得到频繁关联规则。
挖掘频繁关联规则的算法描述如下:
(1)初始状态: L是频繁项集集合, AR是频繁关联规则集合
(2)for all λk(λk是 L的元素,是一个 k-频繁项集,大小为 n){
(3)for all αk(αk是 λk的非空真子集) {
(4)if(αk → βm的置信度 >= minConf) { //这里, m+k=n,其中 αk → βm是一个关联规则
(5)AR =AR ∪ (αk → βm);
(6) }
(7) }
(8) }
(9) return AR;
2 园林数据管理系统
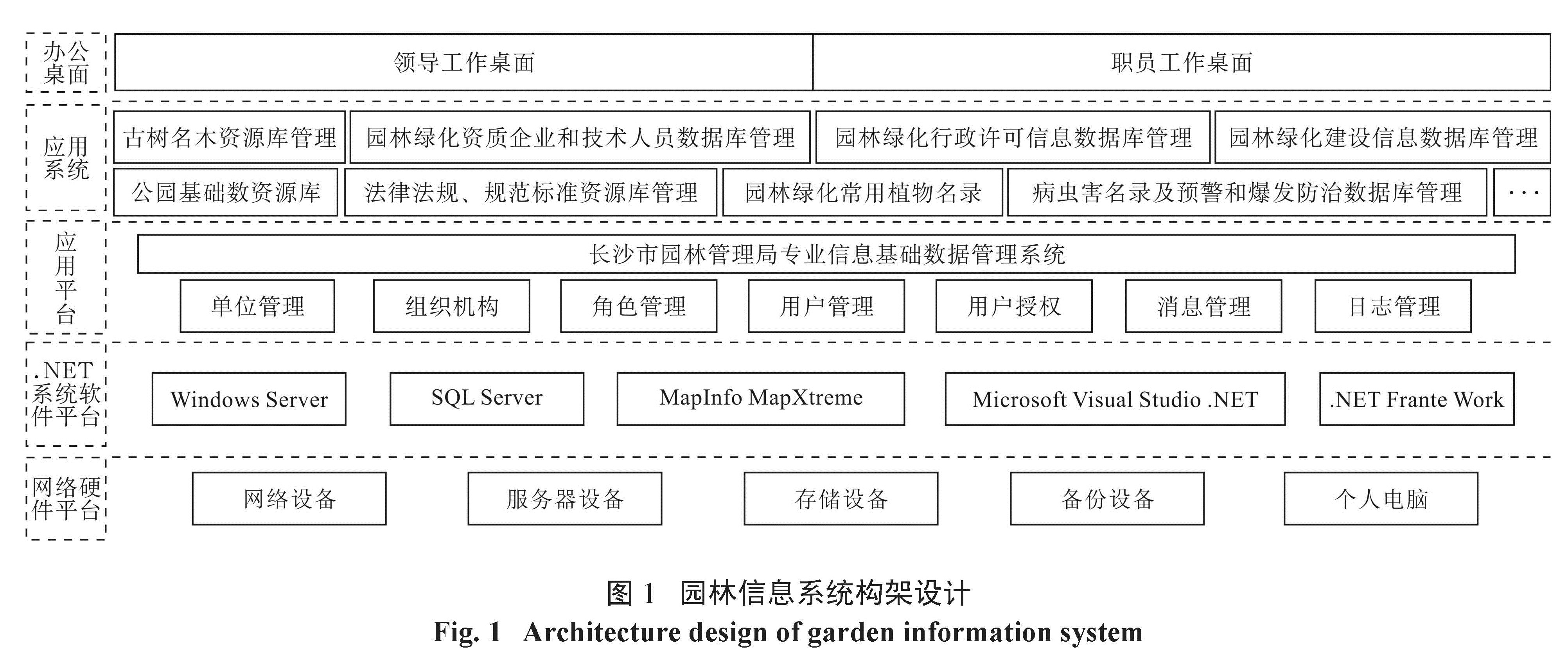
长沙市园林信息系统是在基于局政务网络和 PC SERVER模式下,为了加强全市园林绿化行业管理和行政管理的有效管理,按照规范化、集约化、电子化的管理要求,提高管理效能,实现园林绿化专业信息的“无纸化”科学管理,拟对全市园林绿化专业信息进行编辑、整合,开发构建专业信息基础数据库管理系统。同时利用该应用系统平台,使各种专业信息数据能共享使用,减少信息孤岛,充分发挥信息化带来的实际作用,从而在更大的程度上提高工作效率,实现“电子政府”,推动政府行政职能优化。
2.2 主要技术采用的技术架构设计以先进、成熟的 J2EE关系型数据库 MS SQL Server标准 B/S应用模式, XML、Web Services、EAI等技术为基础,以开放性、标准化为准则,采用组件式、分层次、服务提供者 /使用者间定义接口( Service Provider Interface)、容错等设计思想,保证整个应用系统的稳定性、可靠性和可扩展性。同时在数据交换格式上支持 XML标准,使系统功能最优化,同时将整体系统内部在技术上的相互依赖性减至最低。实现应用系统和数据库系统分离;系统支持内网部署并可扩展政务外网应用。网络拓扑结构如图2所示。
基于园林绿化管理业务发展需要和系统前瞻性的设计思路,系统采用通用的 Browser/Web Server/GIS Server多层结构,由分布在各客户端的浏览器, WEB服务器和 GIS服务器组成,这样,一方面,可以通过园林的内部局域网,可以实现集中办公、统一管理;另一方面,城市居民可以通过 Internet查询园林信息 [5]。
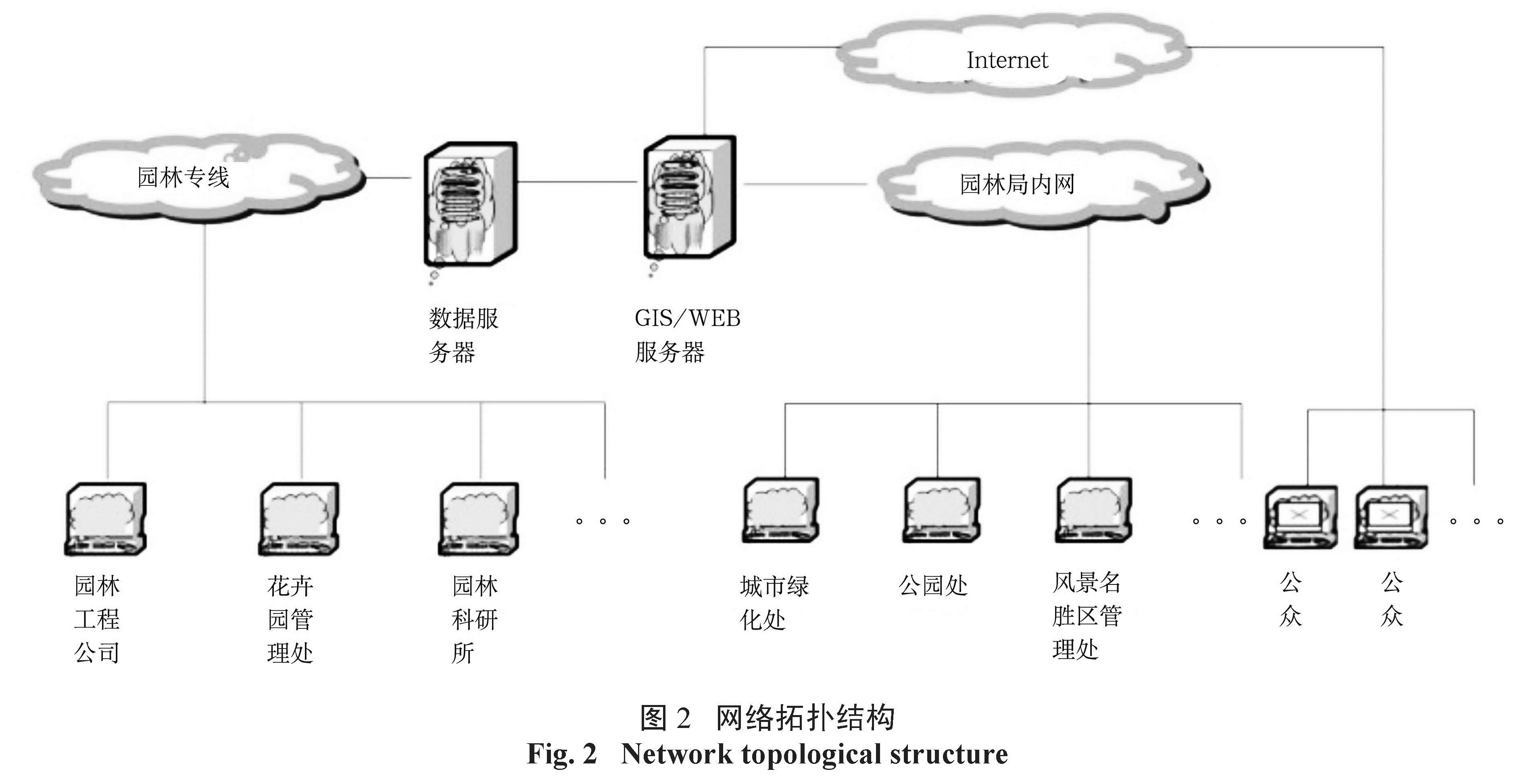
图2 网络拓扑结构
Fig.2 Network topological structure3 Apriori算法在园林系统中的应用
4 总结
数据挖掘技术在园林信息系统中的应用,无论在理论上还是在实际中都有大量的工作要做,本文所做的工作为今后的进一步研究奠定了基础,但仍有许多问题需要解决:
(1)关联规则数据挖掘算法的改进,以提高效率。
(2)更好地利用数据库。园林信息本身属于现存行业中数据量复杂度最高的信之一,因此对于园林数据、影像数据的挖掘工作还有待进一步开展。将数据挖掘与信息系统界面有机结合集成在一起,并采用可视化界面直观显示出来,进一步提高园林管理的自动化 [7]。

图3 园林信息系统输入界面
Fig.3 Input interface of garden information system
图4 园林信息系统查询结果界面
Fig.4 Query interface of garden information system(3)目前还有其它很多数据挖掘方法,比如人工神经网络、决策树、支持向量机等,今后应当继续进行这些方面的研究,以便于更好的为园林信息系统服务,给园林管理部门更高效的决策支持。
- [1]李清峰 .数据挖掘中关联规则的一种高效 Ariori算法 [J].计算机应用与软件 ,2009,21(12):84-86
- [2]刘同明 .数据挖掘技术及其应用 [M].北京 :国防工业出版社, 2005:234:345-350
- [3]邵峰晶 ,于忠清编著 .数据挖掘原理与算法 [M].中国水利水电出版社, 2003,8
- [4]张莉.数据挖掘技术及应用现状 [J].中国石油大学胜利学院学报, 2008,6:34-35
- [5]张斌 .计算机技术在园林环境设计中的应用探索 [J].2007
- [6]卢圣 .计算机辅助园林设计 [M] .北京:气象出版社 .2009
这是一个应用于病虫害防治的一个挖掘实例 ,用于预测某段时间发生虫害的可能性 ,以及可能发生的其他种类的虫害的可能性 ,为病虫害防治提供决策支持。
3.1 设计模型主要采用现在普遍应用的三层架构模式(表示层、逻辑层、数据层)其中表示层负责直接跟用户进行交互,一般是指系统的界面,用于数据录入,数据显示等。用于做一些有效性验证的工作,以更好地保证程序运行的健壮性。如完成数据添加、修改和查询业务等;不允许指定的文本框中输入空字符串,数据格式是否正确及数据类型验证;用户的权限的合法性判断等等,通过以上的诸多判断以决定是否将操作继续向后传递,尽量保证程序的正常运行。数据访问层:顾名思义,就是专门用于进行交互。执行数据的添加、删除、修改和显示等。需要强调的是,所有的数据对象只在这一层被引用,除数据层之外的任何地方都不应该出现这样的引用。
3.1.1 表示层设计在 web服务器的 asp页面被客户浏览器访问响应后,在 shuru.asp页面中,用户输入”霜霉病”或 ID,然后再输入“叶斑病”或 ID确认,进入数据挖掘后的页面,并通过浏览器返回给客户,最后客户就会知道“霜霉病”发病的比例以及“霜霉病”发病时伴同“叶斑病”发病的几率。
3.1.2 逻辑层设计系统架构中体现核心价值的部分。它的关注点主要集中在业务规则的制定、业务流程的实现等与业务需求有关的系统设计,也就是说它是与系统所应对的领域( Domain)逻辑有关,很多时候,也将业务逻辑层称为领域层。
3.1.3数据访问层设计
把系统所需要的数据统统建成数据库,便于数据分析以及数据显示。对应数据库服务器,它的任务是接受 Web服务器对数据库操纵的请求,实现对数据库的操作后把运行结果提交给 Web服务器 [6]。
3.2 部分系统实现3.2.1 Apriori算法实现扫描事务数据库, 计算频繁1- 项集
public Map<Set<String>, Float> getFreq1ItemSet() {
Map<Set<String>, Float> freq1ItemSetMap =
new HashMap<Set<String>, Float>();
Map<Set<String>,Integer>candFreq1ItemSet =
this.getCandFreq1ItemSet();
Iterator<Map.Entry<Set<String>,Integer>>it=ca
ndFreq1ItemSet.entrySet().iterator();
while(it.hasNext()) {
Map.Entry<Set<String>, Integer> entry =
it.next();// 计算支持度
Float supported = new Float(entry.getValue().
toString())/new Float(txDatabaseCount);
if(supported>=minSup) {
freq1ItemSetMap.put(entry.getKey(), supported);
}
}
return freq1ItemSetMap;
}
// 根据频繁(k-1)- 项集计算候选频繁k- 项集
public Set<Set<String>> aprioriGen(int m,
Set<Set<String>> freqMItemSet) {
Set<Set<String>> candFreqKItemSet = new
HashSet<Set<String>>();
Iterator<Set<String>> it = freqMItemSet.
iterator();
Set<String> originalItemSet = null;
while(it.hasNext()) {
originalItemSet = it.next();
I t e r a t o r < S e t < S t r i n g > > i t r = t h i s .
getIterator(originalItemSet, freqMItemSet);
while(itr.hasNext()) {
S e t < S t r i n g > i d e n t i c a l S e t = n e w
HashSet<String>(); // 两个项集相同元素的集合( 集
合的交运算)
identicalSet.addAll(originalItemSet);
Set<String> set = itr.next();
identicalSet.retainAll(set); // identicalSet 中剩下
的元素是identicalSet 与set 集合中公有的元素
if(identicalSet.size() == m-1) { // (k-1)- 项集中
k-2 个相同
S e t < S t r i n g > d i f f e r e n t S e t = n e w
HashSet<String>(); // 两个项集不同元素的集合( 集
合的差运算)
differentSet.addAll(originalItemSet);
differentSet.removeAll(set); // 因为有k-2 个
相同, 则differentSet 中一定剩下一个元素,即
differentSet 大小为1
differentSet.addAll(set); // 构造候选k- 项集的
一个元素(set 大小为k-1,differentSet 大小为k)
candFreqKItemSet.add(differentSet); // 加入候
选k- 项集集合
}
}
}
return candFreqKItemSet;
}
// 获取挖掘到的全部的频繁关联规则的集合
public Map<Set<String>, Set<Set<String>>>
getAssiciationRules() {
return assiciationRules;
}
}


学报简介
中南林业科技大学学报
《中南林业科技大学学报》原名《中南林学院学报》,是中南林业科技大学主办的以林为特色的自然科学学术期刊。该刊1981年创刊,2010变更为月刊,月底出版,国内外公开发行。国际刊号为ISSN 1673-923X,国内刊号为CN43-1470/S。该刊是教育部优秀科技期刊,全国优秀高校学报,湖南省一级期刊。是全国中文核心期刊,中国科学引文数据库来源期刊,中国精品科技期刊,中国科技核心期刊。该刊入编了国内所有的期刊数据库。
主要栏目:林学、生态学、生物科学与技术、植物学、园林、木材科学等。
读者对象:本刊适合于农林院校师生以及农林科研院所、农林管理部门和生产单位的科技和管理人员阅读,也适合于与以上学科和专业有关的其他高校师生和科技人员阅读。